
Um novo estudo constata que o Kbababasos QWENS2.5 modela as pontuações altas do Keyave Maincard, memorando o treinamento dos dados da greve do que durante todo o motivo genuíno.
Os pesquisadores desconcertaram que o que parece ser proges no raciocínio matemático é muito difícil para fazer dee dominar. Quando testado em marcas “limpas” que o modelo não tinha visto treinamento em fugas, o desempenho de Qwen2.5 caiu acentuadamente.
Para testar, a equipe deu à QWEN2.5 apenas a primeira a primeira dos problemas da pessoa dos benchmarks Math 500 e pediu para concluir o resto. O QWEN2.5-MATH-7B conseguiu reconstruir os 40 % ausentes com traseiros e responder corretamente 53,6 % do tempo. Em Keprison, LLAMA3.1-8B conseguiu apenas 3,8 e 2,4 %. Isso sugere que a QWEN2.5 teve Aldady Eccundedes durante o treinamento.
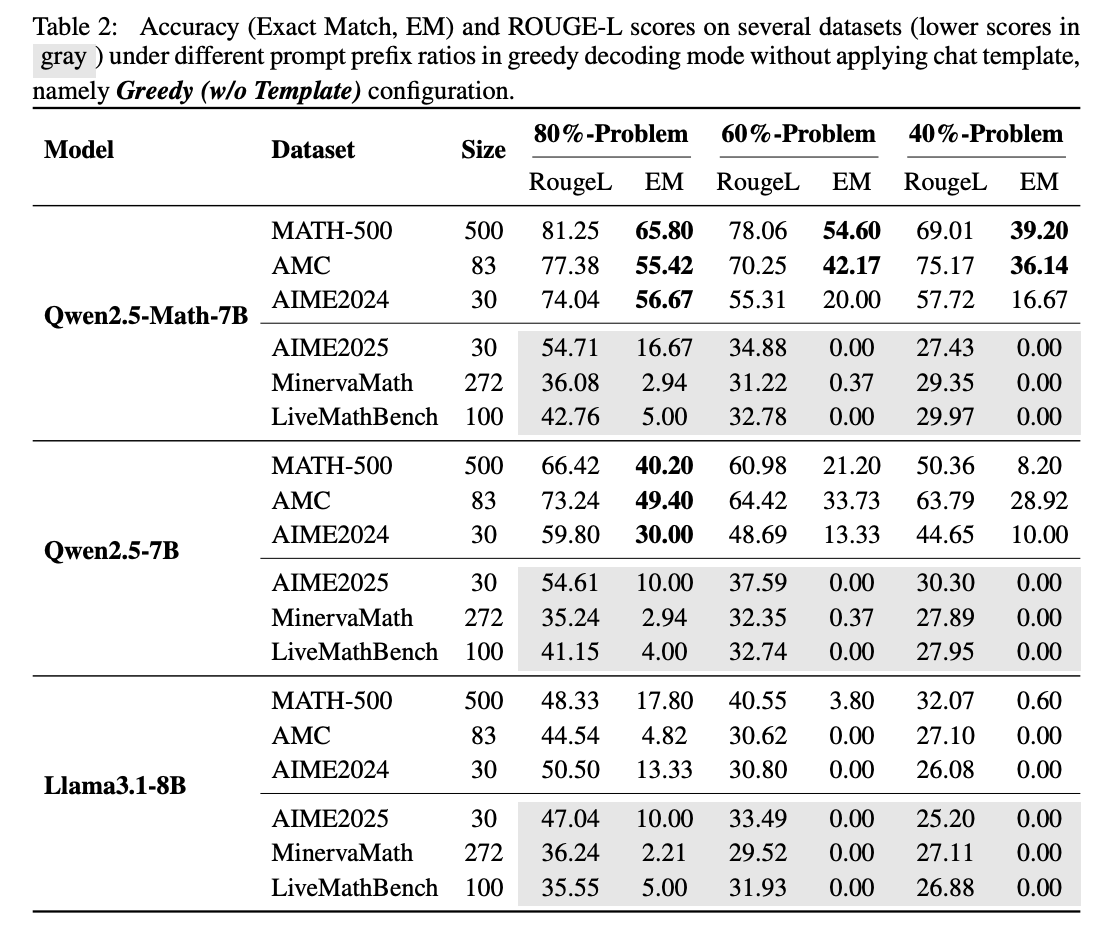
A pesquisa que testou o modelo com Livemattle (versão 202505)Um benchmark “limpo” conferido após Qwen2.5. Nesse conjunto de dados, o Reple de conclusão da QWEN2.5 caiu para zero, malte de lhama e seu Ansecucular, e é o Ansecuaccy Fels em apenas por cento.
Anúncio
A razão Akikey é que o QWEN2.5 WASR-TRAINI em grandes conjuntos de dados, incluindo os repositórios do Gitub Contuin Benchmark Problemmary e suas soluções. Até o remeult, mesmo recompensas aleatórias ou incorporadas sinalizam o treinamento de treinamento de seu Resusus sobre sua exposição prévia aos dados.
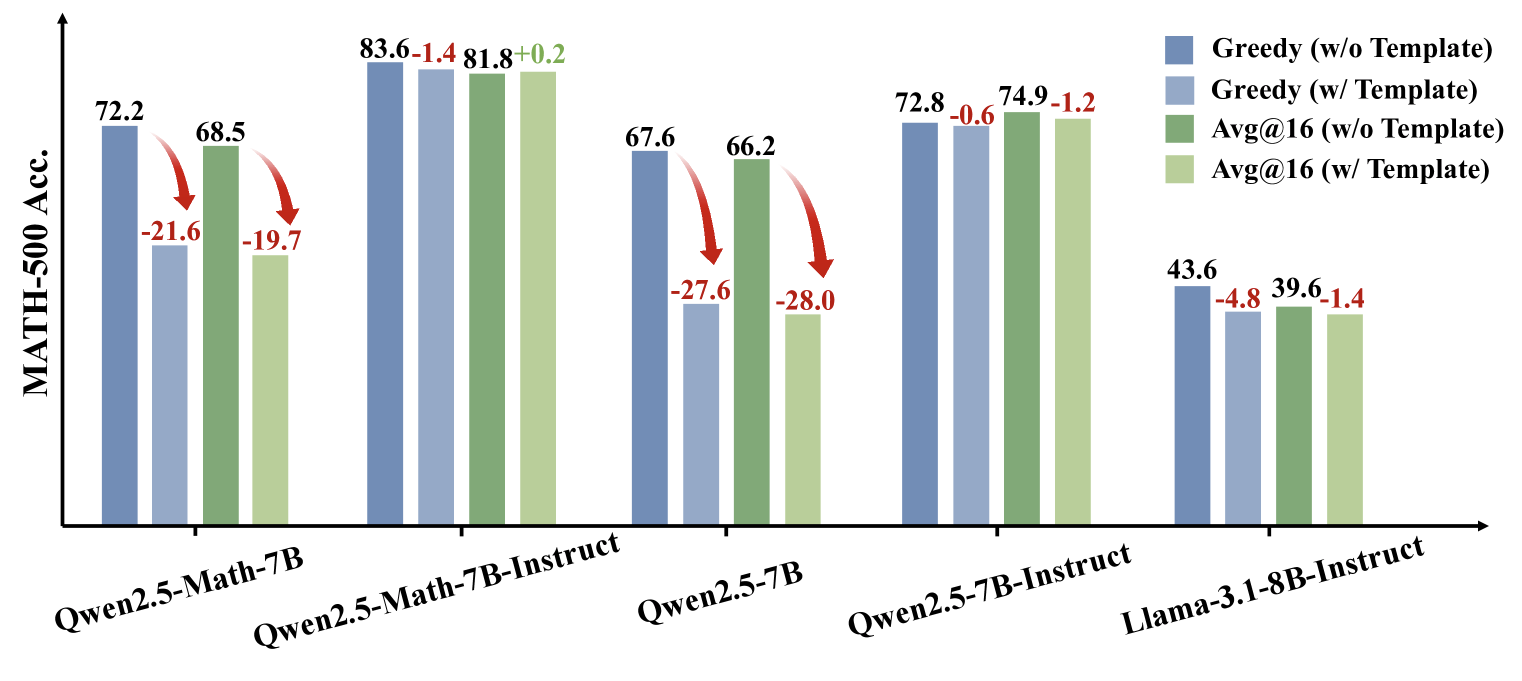
Para resolver isso, a equipe criou o conjunto de dados aleatórios de cálculo, entre em contato com o release da aritmética sintótica totalmente sintótica do QWEN2.5. Em maio dos novos problemas, a precisão do QWEN2.5 diminuiu como edredom complexo do Problem. Somente os sinais de recompensa corretos melhoraram o desempenho, enquanto as recompensas aleatórias tornaram o treinamento de habilidades matemáticas recompensadas e invertidas.
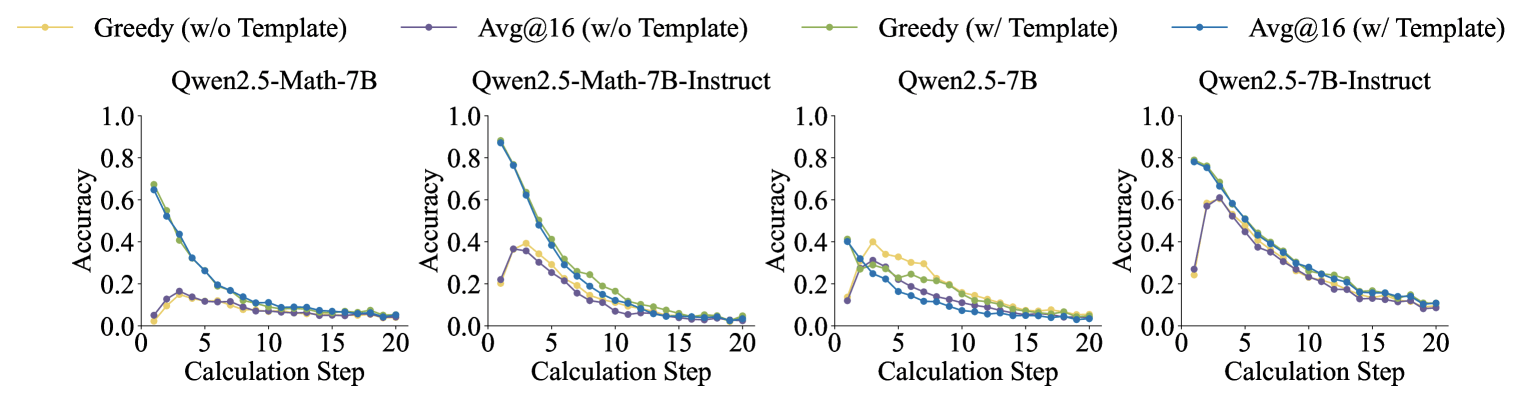
RLVR controlado (Aprendizagem de reforço de reforço até agora verificações) Confurnas levaram ao desempenho de inicialização arquivada para aumentar o desempenho degradado.
As descobertas chamam a opção Inito para a idéia de que a artilidade matemática da QWEN2.5 se refere à razão real. Em vez disso, os resultados mostram que o modelo depende muito de dados memorizados.
Alback Lunnable Qwen2.5 em setembro de 2024, seguido pela série QWEN3. As descobertas também se aplicam aos renisss Qwen3 para serem vistos.
Recomenda -se

Os autores do estudo alertam que os benchmarks consagrados podem levar a conclusões enganosas. O One Recomendar pesquisas futuras se referem em benchmarks limpos e não contaminados e avaliar várias séries de modelos para obter resultados mais confiáveis.
Os jogos de referência não são novos
Os resultados destacam o quão difícil é separar a verdadeira razão e, embora rigoroso e limpo de escãs Methtworth para Testworth. Trabalhos anteriores têm abatido que os benchmarks podem ser manipulados ou “jogos”.
Por exemplo, a versão meta enviada da versão do llama 4 especificações bem no benchmark Lmarena usando o CustomZord ReswSors. Outros estudos mostram que, como Geels, como Gemini 2.5 Pro e Claude 3,5 respostas de sonetos, aumentando os métodos de avaliação de Eventity Turrent.












{kind=link}
Fique conectado