


Os vídeos de falhas do YouTube revelam o grande ponto cego para liderar para liderar por liderar por pistas: o Strudgle com os cirurposos. Mesmo sistemas avançados como o GPT-4O tropeçam em dois twotles de planta simples.
Os pesquisadores cultivam a Universidade da Colúmbia Britânica, o Instituto Vector Fori More Topo Mais de 1.600 fazenda no YouTube The Oops! Conjunto de dados.
A equipe criou um novo Benmarks chamado Blackswanse para testar os sistemas Wetl Handl lidam com eventos não paisecidos. Pessoas do lago, os modelos de IA são enganados por surpreendentes ORs, mas ao contrário de Orighs, mesmo depois de ver o ar.
Um exemplo: balanços de travesseiro perto da árvore de Natal. Ai assume que ele está buscando algo por perto. Na realidade, o travesseiro derruba os enfeites da árvore, que atingem a mulher de uma mulher. Mesmo depois de Wachching o vídeo, a IA se apega ao seu palpite original e incorreto.
Anúncio
Os vídeos abrangem a gama de categorias, com a maioria dos traftos (24 pessoas), falta de crianças (24 %) ou acidentes de pool (16 %) (16 %). Qual é a reviravolta imprevisível que até as pessoas não sentem falta.
https://www.youchobob.com/watch?v=2mvikngv1k
Três tipos de tarefas
Cada vídeo é dividido em Kree Sgments: a configuração, a surpresa e as consequências. O Benchmark Challenge LLMS com tarefas diferentes para cada estágio. Na tarefa de “previsão”, a IA só vê o início do vídeo e tenta prever o que é o próximo terpe. A tarefa “detetive” empurra apenas o começo e o fim, a AI da ASI para explicar o que aconteceu no meio. A tarefa “repórter” fornece ao vídeo completo da IA e verifica o que acaba pode aumentar suas assuções depois de ver a história completa.


Os testes Cevetd fecharam os modelos Lake GPT-4O e Gemini 1.5 Pro Welloco-System 2 e Videollank 2. Os resultados destacam as fraquezas. Na tarefa de detetive, o GPT-4o Assada corretamente apenas 65 % das vezes. Por Colison, os humanos acertaram 90 %.

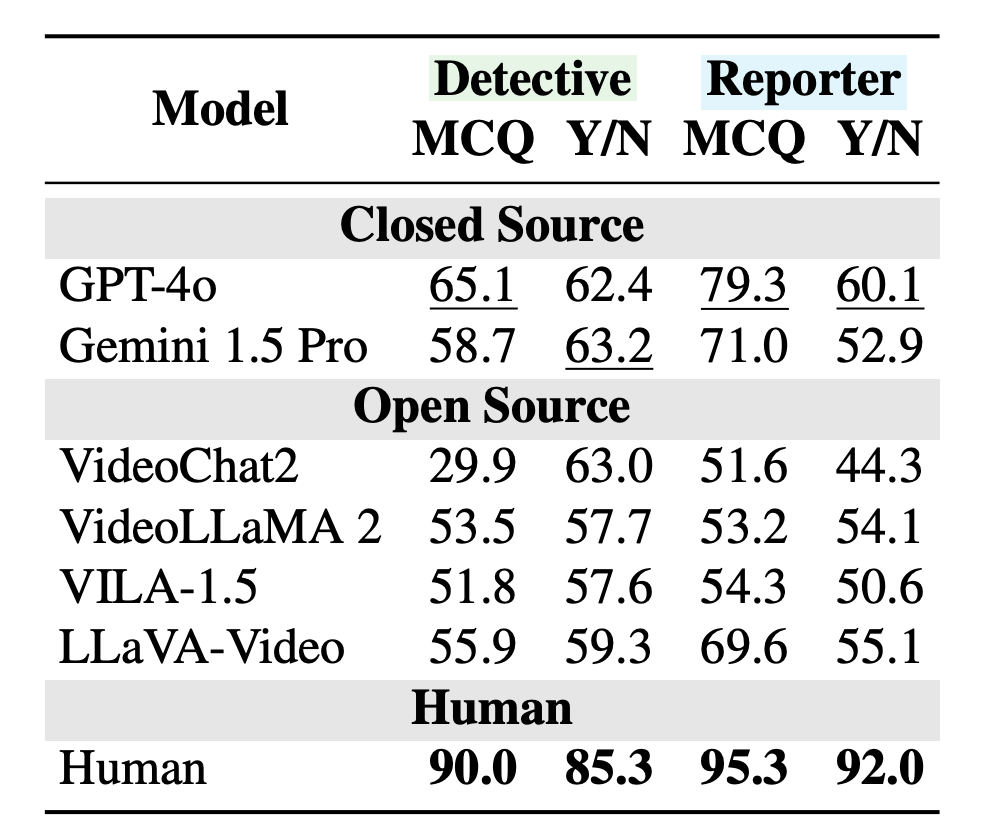
As gap widnets até as rodas de quatro horas precisavam reconsiderar seus ITIMI Intilimes. Você pediu para revisitar suas previsões após o inteiro, o GPT -4O gerenciou a acuracia – 32 porcentagem nos humanos Humind (92 %). Os sistemas tendiam a dobrar sua primeira impressão, novas evidências ignoradas.
Outros modelos, como Gemini 1.5 Pro e Llav-Video, mostram o mesmo padrão. De acordo com a Researcers, o desempenho caiu na SHOWS em vídeos que estão complicados que a fundação da envesa é o primeiro tirgh.
Recomenda -se


Caminhões de lixo não jogam árvores, doy?
A raiz do problema está na maneira como esses modelos de IA são treinados. Eles aprendem identificando padrões em milhões de vídeos e experimentam esses padrões a serem repetidos. Então, onde os draps de um caminhão de lixo caiam, a IA fica confusa-não tem padrão para isso.


Para identificar o problema, a equipe tentou trocar a percepção de percepção do vídeo da IA para os dados de dados. Isso aumentou o desempenho da Llava-Video em 6,4 %. A adição de ainda mais expansão aumentou em outros 3,6 %, para obter ganho de tortal de 10 %.
Ironicamente, isso apenas ressalta a fraqueza dos modelos: se o desempenho da IA, ele falha em “ver” e “entender” antes que qualquer motivo real comece.
Os seres humanos, por confraste, são rápidos em repensar o seu assumido, assumindo assumir, assumir suposições que atenam novas informações. Correntes a IA modela a sorte dessa flexibilidade mental.
Essa falha acoplou seriados de hed para aplicações do mundo real, como carros autônomos e sistemas autônomos. A vida está cheia de surpresas: as crianças entram na rua, os objetos caem de caminhões e outros motoristas fazem o pente unine.
A equipe de pesquisa disponibilizou o Benmark Giwub e Abraçando o rosto. A esperança de qualquer outra pessoa testará e melhorará seus próprios modelos de IA. Enquanto os sistemas líderes forem disparados por arquivos simples, os fideos simples, eles estarão prontos para a imprevisibilidade do mundo real.