
Albaba introduziu o QWEN-Image, 20 bilhões de parâmetros, projetado para o texto de alta fidelidade, renderizam imites passados.
De acordo com o Deverpopers, o Qwent-IMGE pode mão de stotott visual sirides embalados com o conteúdo contado contado contado contatado. O modelo também para promorates bilíngues e pode alternar sem problemas entre os idiomas.


Além da geração da IGAGE, Qwen-Image traz de terno de ferramentas de Educação. Os usuários podem alterar os estilos visuais, adicionar ou remover objetos e ajustar as poses das pessoas dentro de Ithges. O modelo NSO abrange a visão clássica de visão computacional tsks Lake estimando a imagem, deposição de imagem, deposição de imagem, que descreve a arken deputa ou.

De acordo com o Relatório TécnicoA arkecture do modelo é construída em fazendas três partes: os textos da mão QWEN2.5-VL e o Difleson multimodal negocia as saídas finais.
Anúncio
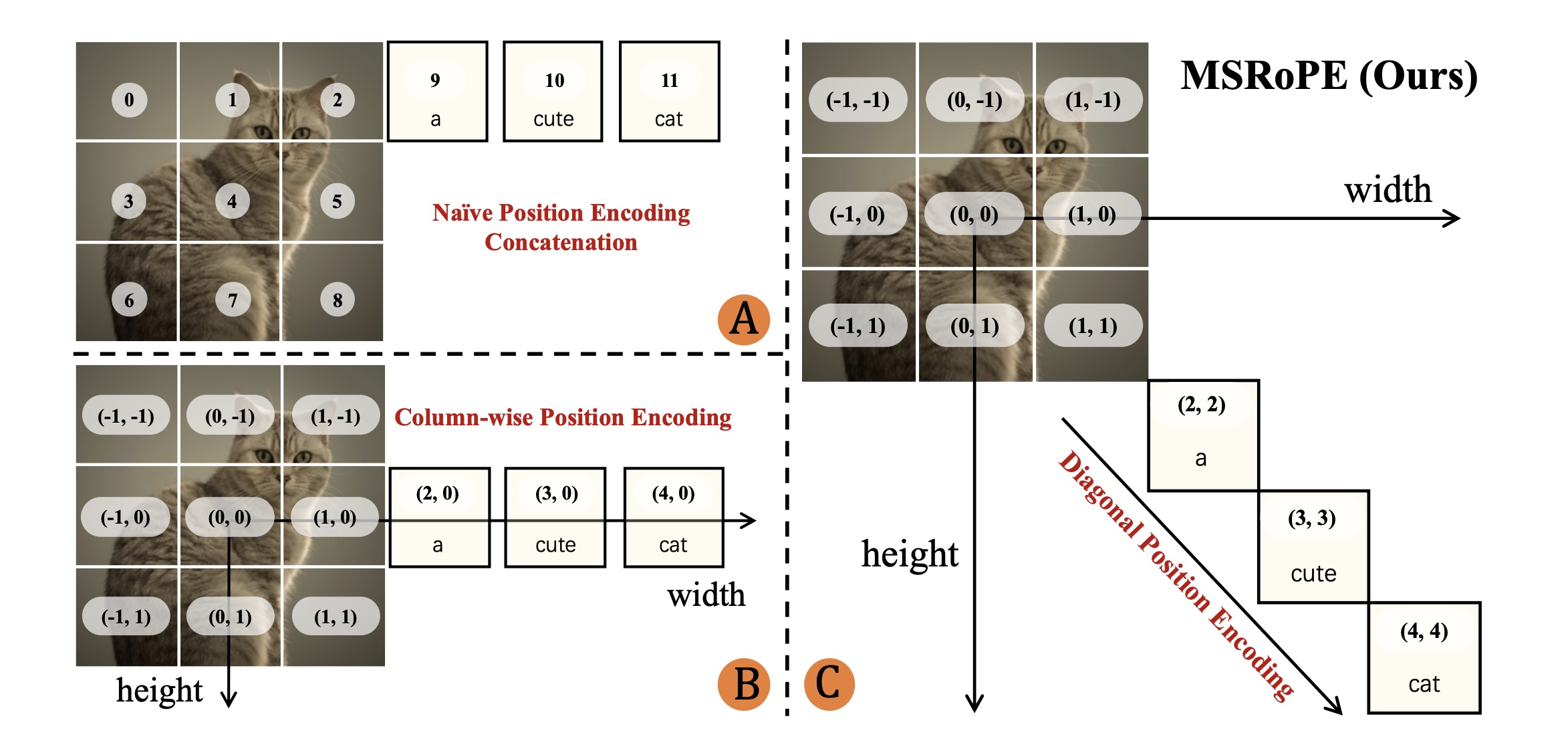
Uma nova abordagem chamada msrope (corda escalável multimodal) aprimora como o modelo de texto positivo nas imagens. O senspe é a técnica para codificar relações espaciais em modelos multimodais. Diferentemente dos métodos tradicionais que tratam o texto uma sequência simples, o msropope pretende o texto elementar no diameal da imagem. Isso permite que o modelo precurie o texto de local em diferentes imoluções e melhora o alinhamento entre o texto e o conteúdo da imagem.
Treinamento de dados de contos exclusivos de IA
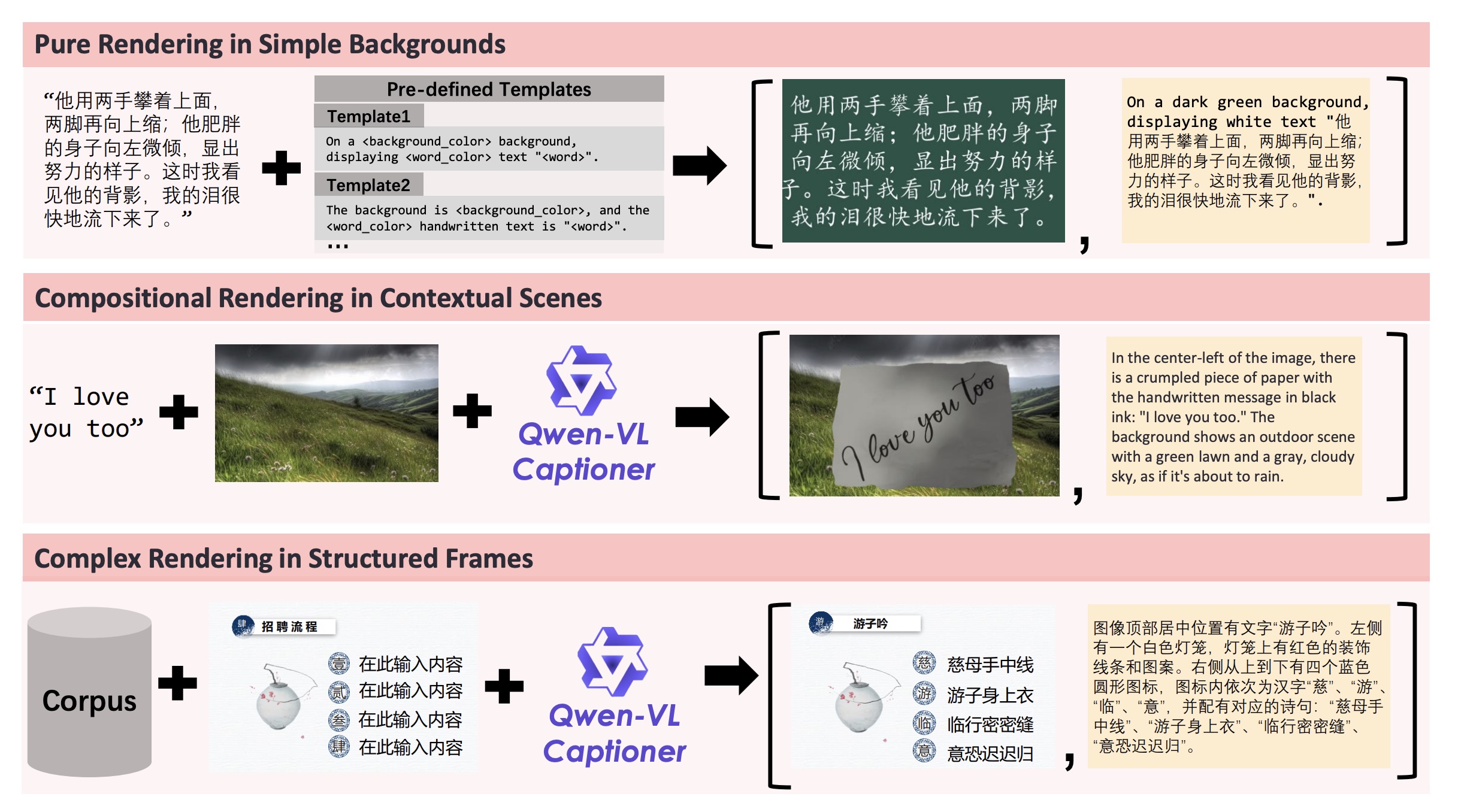
A equipe de Qwen diz que os dados de treinamento do modelo falam em quatro categorias: Nature Ours (27 %) e sintet) e dados de sintet (5 %). O pielene de treinamento evita especificamente as imagens gennetas de IA, concentrando-se em prolleges criadas pelo texto.
Proces de filtragem de vários estágios RomOves Conteúdo de baixa qualidade. As estratégias de árvores completam os dados de treinamento: redução pura (licitação simples (texto em realista (texto em cenas realistas) e comux ratets.
Batendo modelos comerciais em áreas -chave
Para avaliação, a equipe construiu Uma plataforma de arena Os usuários de prostituta imagens classificadas Anonymous agricultam diferentes modelos. APTER MAIS DE 10.000 COMPARES, QWEN-AMAGEM classificados, superando modelos comerciais como GPT-Image-1 e Flux.1 Contexto.
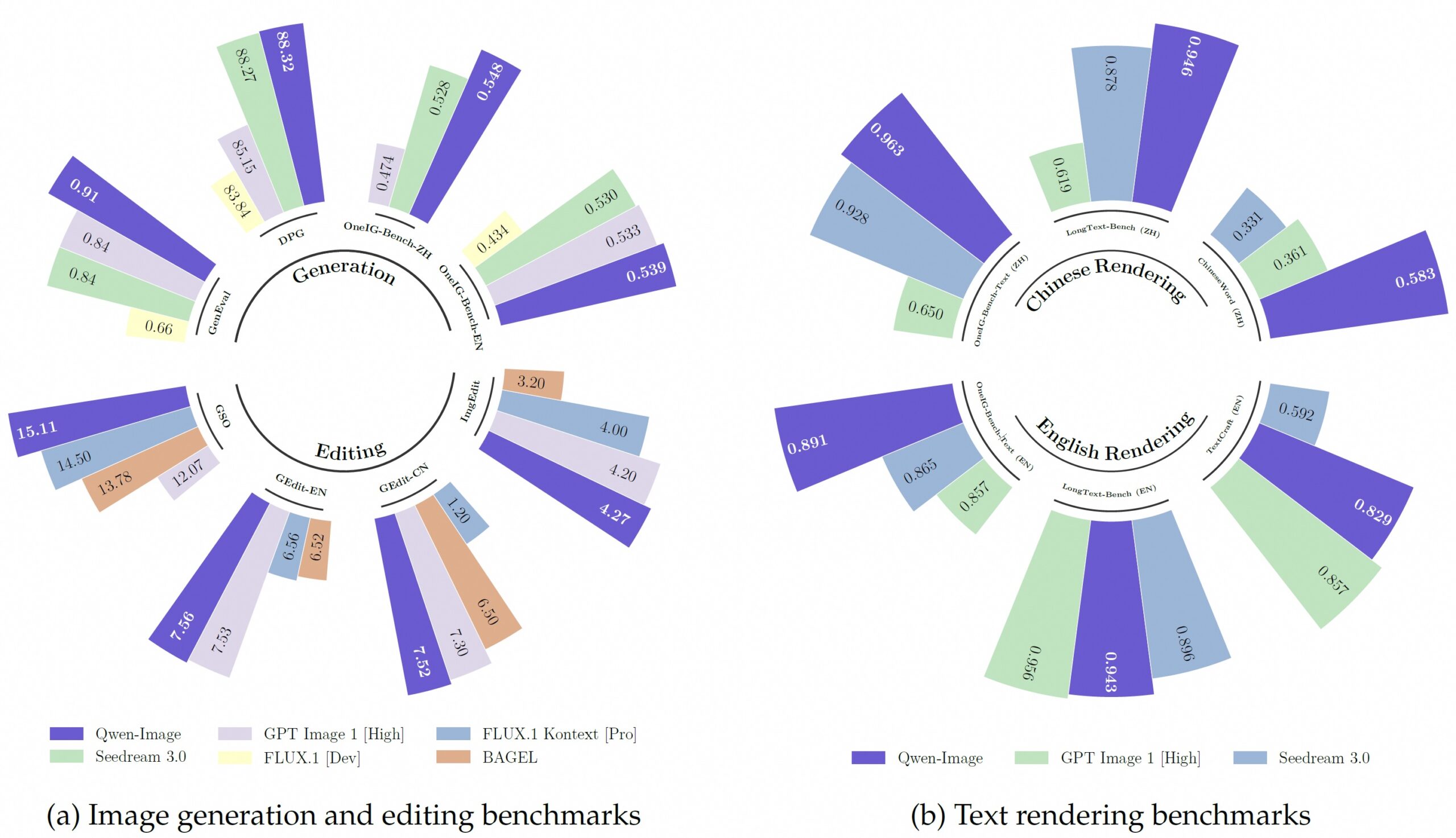
Benmar Resultados de backup de descobertas da ONU. No teste geneval para gaxificação objetiva, o Qwen-Image Scodd 0,91 após treinamento adicional, à frente de todos os outros modelos. O modelo também mantém a vantagem clara na renneração de caracteres chineses.
Recomenda -se

A pesquisa Seee Qwen-Image como um passo em direção a “interfaces do útero em linguagem da visão” que integram firmemente texto e imagem. Olhando ahhead, Albaba é Woggond em plataformas unificadas para entender e geração de imagens. Recentemente, a empresa Undeed Qwen VLO, outro modelo conhece sua forte capacidade de texto.
Qwen-Image está disponível gratuitamente Giwub e Abraçando o rostocom um Demoção ao vivo para teste.











{kind=link}
Fique conectado