
Pesquisas sobre a NVIDIA dizem que a indústria de IA está focada demais em modelos de idiomas ampliados, estratégia que eles estão arqueiros e ambientalmente não impedidos.
Em um recente PapelOs agentes sugeridos do Moster poderiam correr da mesma forma em modelos de idiomas pequenos (SLMs) e instar as empresas a reformular sua APROACH.
O mercado de agentes da LLLM APIS THOPER está em referência a US $ 5,6 bilhões em 2024, o Butlion Infrastures atingiu US $ 57 bilhões, 10-1 Gap. “Esse modelo de opersal depende da indústria – tão profundamente ilegal, de fato, intensas os betuits de capital fundador”, escrevem o TI.
O SLMS, que define um modelos abaixo de 10 bilhões de parâmetros, “visualizações ineldes” e “necessariamente mais econômico” para cargas de trabalho do agente Mott.
Anúncio
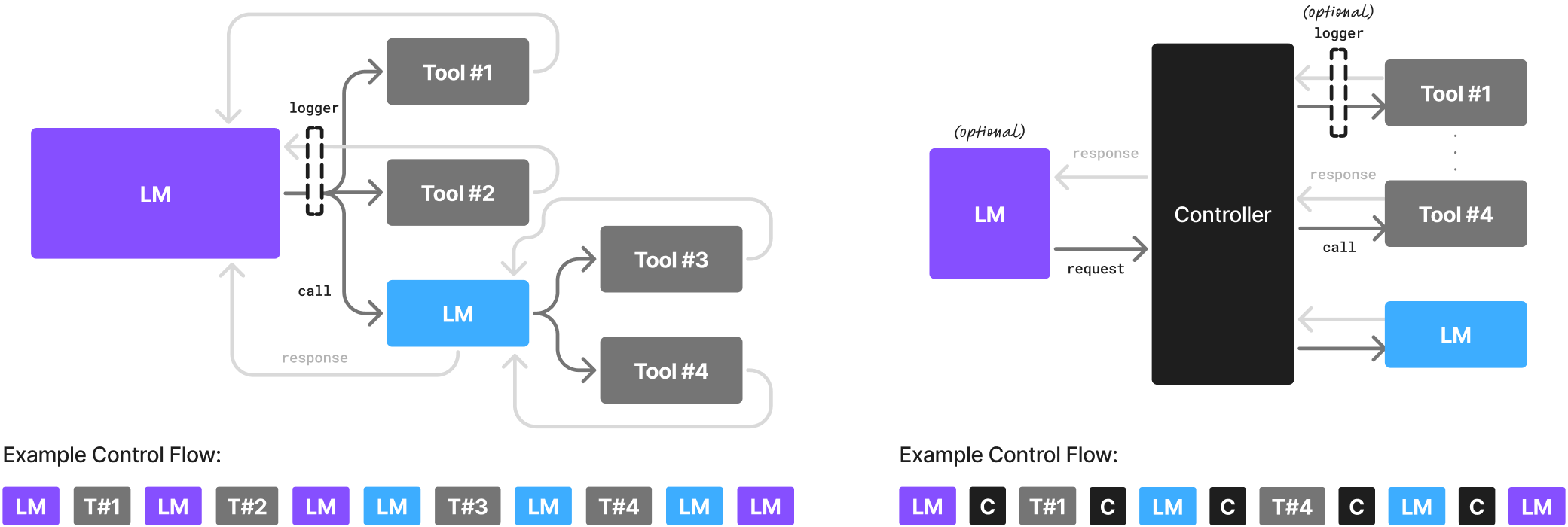
A pesquisa argumenta que modelos menores podem mechar ou vencer os maiores. Eles citam PII-2 da Microsoft, que dizem rivais LLMs de 30 bilhões de papéis em razões e código executando 15 vezes mais rápido. Nvidia’s Modelos NMotron-HCom até 9 bilhões de parâmetros, o relatório entrega uma acuracia semelhante a LLMs de 30 bilhões de parateters usando os árvores usando a computação de árvores. O YESSO reivindica Deepiseek-R1-Distill-Qwen-7b e a Retro Match da depmind ou superaram os modelos proprietários de muito tempo em tarefas principais.
A economia se inclina pequena
A pesquisa da NVIDIA diz que o Math Favors SLMS. Execução do modelo de 7 bilhões de parâmetros 10 a 30 vezes menos um LLM de 70 a 175 bilhões de pacotes, Sye de face de requisitos de computação. O ajuste fino pode ser feito em um instações de horas da GPU da Fugi, usando pequenos modelos em Ach Freter para se adaptar. Muitos também podem Runo Lovally no consumidor hardwor, que attry e dá um trole sobre seus origem.
A equipe também moldam seus parâmetros mais episódicos de givens – um IFFIENCE PARA O GIVY SES IMPORTO. Os agentes da Arguina são os agentes da IA raramente Ned toda a gama de capacidades que uma LLL oferece. “Os agentes da AI AG são o portão de portão fortemente instruído e cooquitado externamente para o modelo de idioma da IA”, o modelo.
As tarefas do agente MOSP são repetidas, por pouco escopo e não são convertidas, qual o SLMS de máquinas especializou o SLMS Fine Tux para os formatos de melhor ajuste. Sua recomendação é criar SLMs de agente hetronea por padrão, reservando os modelos maiores.
Wy slms não estão assumindo o controle
De acordo com a equipe da NVIDIA, as maiores barreiras são o investimento da indústria e a sorte dos Gechmarks públicos sobre os modelos pequenos capazes de HEW se tornam.
Recomenda -se

Eles estabelecem um plano de seis etapas para misturar os turnos: coletando e selecionando os toques, ajustando fino melhorando com o tempo. Nos estudos de caso, o que encontra que 40 a 70 % da LLM Quest e Cradle Coupd Bea Hand Nust Nust Hands.
Os pesquisadores observam que, para muitos, a mudança para o representante do SLMS, mas “à luz dos colls de resing. O Mistral recentemente apóia a visualização quando lançou a Data Datiled Date Dat Dat Date
É um sem vergonha para a Nvidia, um dos maiores benéficos benéficos, para fazer essa argumentação. Mas empurrar os modelos menores e mais cheios pode agrupar as marcas de horas extras e ajudar a incorporar a tecnologia mais profundamente em todos os negócios e dispositivos de consumo. Nvidia é Buscando feedback Da comunidade e planeja publicar resfenses selecionados online.












{kind=link}
Fique conectado