
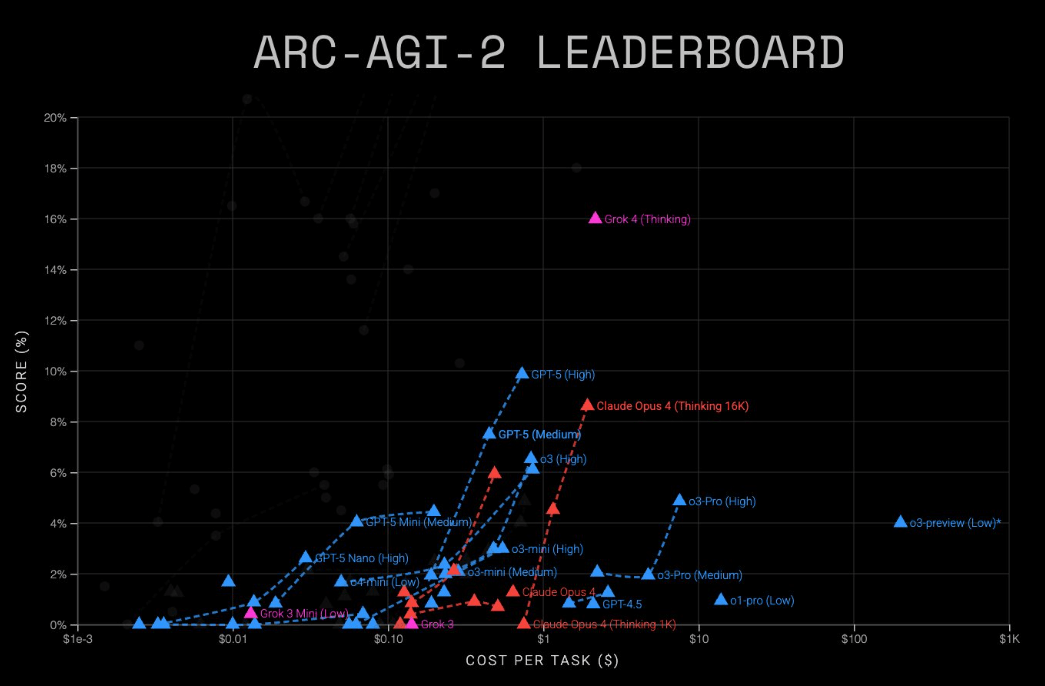
No benchmark AG-AG-2, que testes da razão geral, GPT-5 (alto) SCODD 9,73 por tarefa, acumulando o prêmio ARC.
Grok 4 (pensando) DUD melhor no ARC-Agi-2 a Roghly 16 %, mas no Mech High High High High High High High High High High High High High High High High High High High. Os benchmarks ARC-AG orarão a refatação sobre a memoranização e os modelos de classificação, tanto pela acumulação quanto pela poluição do custo.
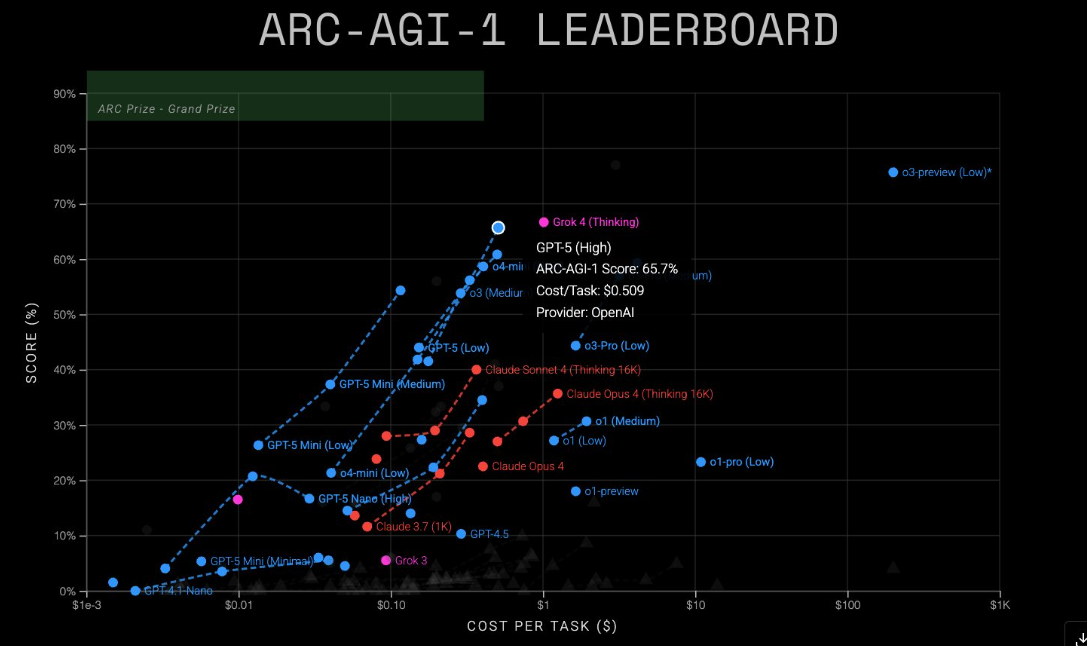
No teste ARC-AGI-1 exigente de Lesming, Grok 4 novamente levou a cerca de 68 %, edegando 5 a 65,7 %. O GROK 4 custou cerca de US $ 1 por tarefa, o que GPT-5 entrega supra por US $ 0,51. Isso é GPT-5, o melhor valor por enquanto, o CHAI HUST XAI O CHAIR restringe a lacuna com as mudanças de chanagem de preços.
Versões Lighter, CHEAPRER ARRSO ALOILIBLE. O GPT-5 Mini Anaved 54.3 Percet no AGI-1 (US $ 0,12) e 4,4 % no AGI-2 (US $ 0,20). O GPT-5 Nano conseguiu 16,5 % (US $ 0,03) e 2,5 % (US $ 0,03), respectivo.
Anúncio
De acordo com Arc Prie, Cedo, ainda Testes não oficiais são al Em andamento Para a referência Intective ARC-AG-3, que requer modelos tarefas Thryngs Thrdh Grods and Error na configuração semelhante ao jogo. Enquanto os humanos se divertem, Thry Thry Challenge, os agentes da Mosti ainda lutam com os jogos visuais de quebra -cabeça.
Vale a pena que o Hero Strong Mostring Hero da Grok 4 não tem o modelo forte que se sobrepôs o Plasd Xai de Assumação de Referência de Referência de Regras.
O quebra-cabeça de previar o3
O OPEAAI não mencionou o prêmio ARC duplo sua apresentação do GPT-5, apesar de seu significado nos modelos anteriores de almoços de modelos. Natavelmente, em O teste arc-agi-1, O modelo de previsão de O3, introdução em dezembro de 2024, ainda detém a pontuação máxima da Alsary 80 %, Althung, também de modelos compactos.
As informações relataram que a Onaenai teve que fazer grandes reduções na previsão de O3 para a empresa posterior, precisa comentar. O prêmio ARC confimou o resultado fraco para o modelo O3 relerado publicamente no final de abril.











{kind=link}
Fique conectado