
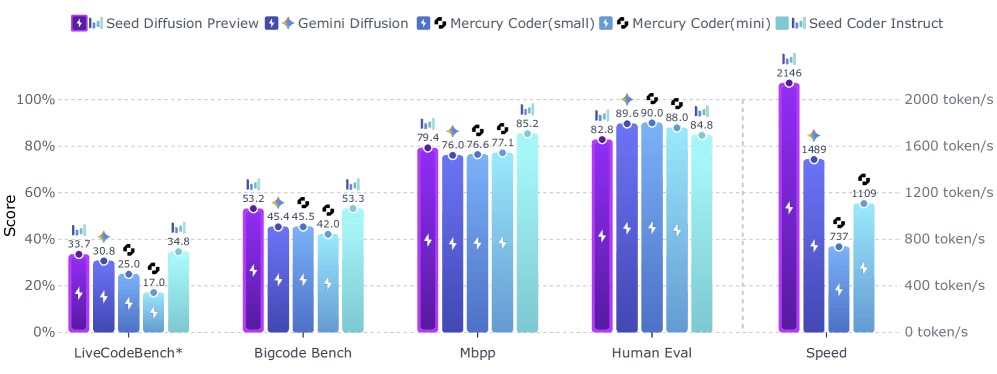
A visualização de diffusão de sementes é o modelo de AI da experiência de Byted para geração de código, projetada para gerar Tyens no palto de Onee no momento. A empresa diz que atinge SPADs de 2.146 tanns por segundo nas GPUs Nvidian H20.
A diferença de sementes nos visualiza uma abordagem “diferenças de estado discreto”. Enquanto os modelos de diifas geralmente são construídos para o Contintus Data Likgts, a Bystence possui adaptuts, o ByStechence possui adaptações e hapte hapte Dechta Soch como texto e código.
Em vez de controlar cada tayen em sequência, o modelo reconstrói o código do estado barulhento e cheio de soldados. Várias seções de código são genetivas, graças a um artigo do Transformer que se aproxima da previsão do Parlel, não apenas à procissão passo a passo padrão.
Esse fluxo de trabalho paralelo leva a uma geração mais rápida de polegada, mas de acordo com o nome do byted, os reninandes de qualidade de código são altos. Nos testes de referência, a visualização de difusão de sementes teve um desempenho competitivo com outros modelos e destacou -se especialmente para tarefas de edição de código.
Anúncio
Para resolver os problemas em diferenças mascaradas padrão, nomes de contas usando o processo de treinamento de pré-estágio. A primeira etapa depende do treinamento baseado em máscara, substituindo os pagamentos do código de que os placas especiais.
Mas isso às vezes pode fazer com que o modelo seja cópia desmascarada de tagarelas sem verificá -los. Para corrigir isso, a equipe adicionou uma segunda fase: treinamento e desertos de treinamento baseados em edição. Isso força o modelo a revisar e coryct todos os Tayens, não apenas o mascarado.
A equipe também optou pela ordem de genição de geração, estrutura de código de tapple e deppencecas. O modelo One TROINO TROINO no conjunto de dados grandes e filtrados de sequências de alta qualidade criadas pelo modelfo pré-treinado.
Auto-otimização de decodificação do parlal
Embora os modelos de diferença devam, em teoria, a decodificação do Parlel, que a ação, isso é reclamado. Cada etapa de inferência do parlalel é exigente compatível, e o número de medidas pode prejudicar a qualidade.
Bystence abordou isso treinando o modelo para opelizar seu próprio procesos de gession “aprendizado na política”. O objetivo é minimiyhazer o número de etapas, a casa, o modelo de verbicação verifica a qualidade da saída.
Recomenda -se

Para uso praticático, a visualização de sementes diferencia o código do Parlel em blocos, mas o Kogical Ormen entre os blocos. A equipe também pilha de software OTS de Twacher OTS para pances de diffusão, usando a estrutura da FINTNA criada para a coisa da carga de trabalho.
A visualização de diferenças de sementes é enferida da resposta do norte da resposta do norte, que foi anual em maio e também a geração de código TARGS. Bystence diz que é para manter a experiência com o CONCON e adaptar a abordagem por uma razão mais complexa. Ti é a Demonstração disponível aqui.












{kind=link}
Fique conectado